11 - V1 Ideation Skill Experiment: Testing Local Models on Feature Ideation
I ran 8 different Qwen 3.5 model quantizations through an ideation skill to see which configuration produces the best structured feature ideation session for my Aily app.
Why Test Ideation First
Ideation is the first step in my feature workflow. Before I create a PRD or plan tasks, I need to sharpen an idea, pressure-test assumptions, find contradictions, capture the user’s actual words. If a local model can handle this, it can save real time on every new feature I build.
The problem is that ideation is not just Q&A. It requires strict round structure, contradiction detection, and vivid language preservation. These are hard rules to follow and a perfect test for reasoning quality.
I tested two model families: Qwen 3.5 27B (Dense architecture) and Qwen 3.5 35B A3B (MoE architecture, 35B total, 3B active). Each family got 4 quantization variants. Same task, same skill, different models.
Test Setup
All models ran on a Minisforum MS-S1 Max AI with these parameters in LM Studio. Sessions were done in OpenCode:
| Parameter | Value |
|---|---|
| Context Length | 262144 |
| GPU Offload | Full |
| CPU Thread Pool Size | 16 |
| Evaluation Batch Size | 8192 |
| Max Concurrent Predictions | 1 |
| Try mmap() | Disabled |
| Flash Attention | Enabled |
| K Cache Quantization Type | Default |
| V Cache Quantization Type | Default |
| Thinking | Enabled |
| Temperature | 0.6 |
| Top K Sampling | 20 |
| Repeat Penalty | 1 |
| Top P Sampling | 0.95 |
| Min P Sampling | 0 |
All sessions and results were analyzed and evaluated by MiMo V2 Pro Free in OpenCode Zen.
The Skill Structure
The ideation skill lives in Skill/ideation/ and follows a strict 6-step flow:
- Scan Workspace — read
README.md, globdocs/**/*.md, extract project context - Open Session — introduce the interviewer role, ask what the user wants to build
- Question Rounds — 4+ rounds with assigned themes: Problem → Users → Constraints → Value → Follow-up
- Detect Stop — wait for explicit stop signal before writing
- Write Ideation Document — fill the template using the user’s own words
- Handoff — hand off to the
create-prdskill
The skill has reference files:
- ideation-template.md — document structure with Problem, Solution, Value, Open Questions, and Next Steps
- questions-extended.md — extra questions for round 5+
Key rules: do not propose solutions, do not skip to writing, do not accept “it depends”, name contradictions when you spot them, and never sanitise vivid language.
The Command Problem
Small models rarely read skills and reference files on their own. During testing, most models skipped
ideation-template.md or questions-extended.md entirely — they loaded the skill but never opened the reference files.
This breaks the entire flow: no template, no extended questions, no proper document structure.
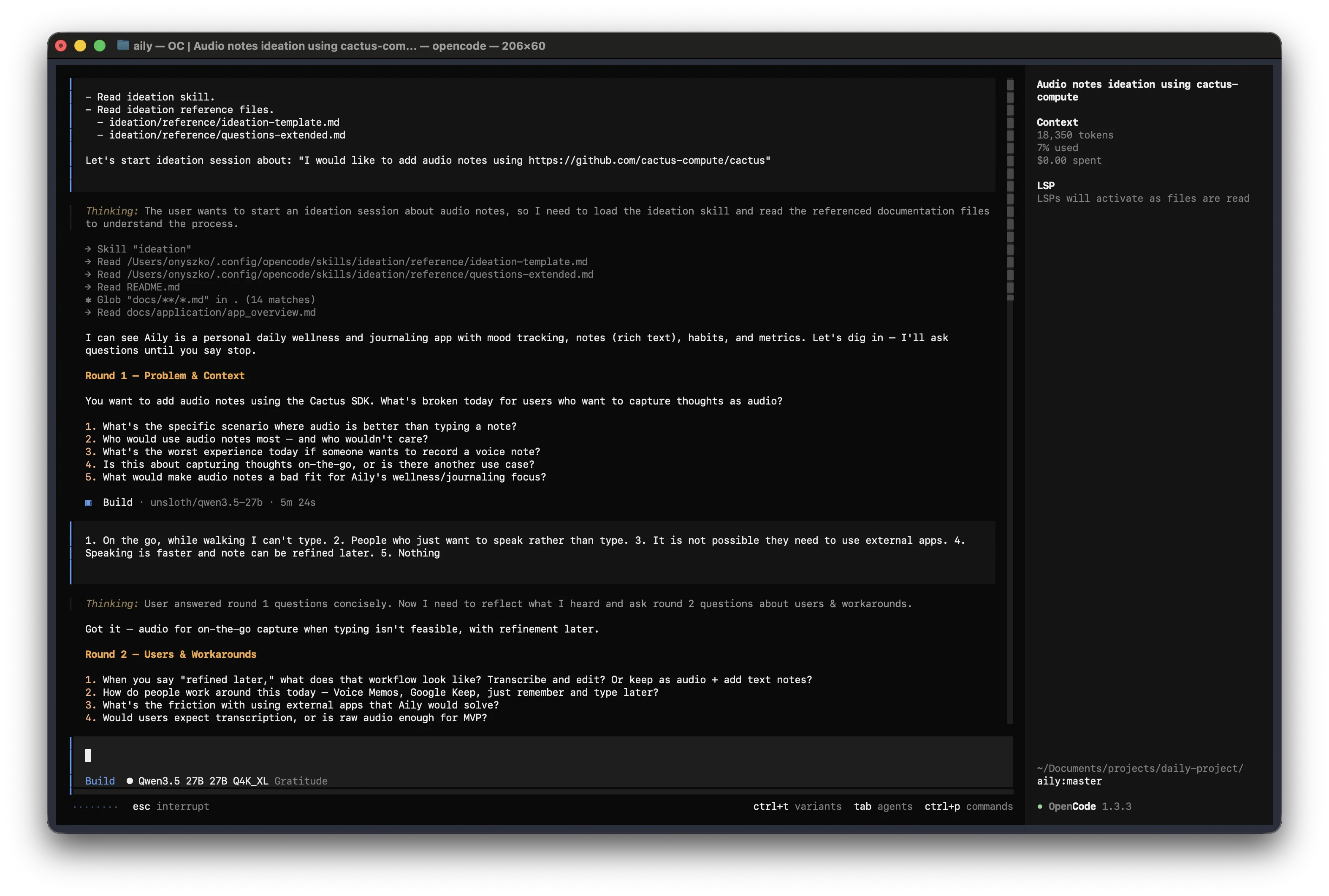
I had to create a command (lets-ideate) that explicitly tells the model to read the skill and reference files before starting:
- Read ideation skill.
- Read ideation reference files.
- ideation/reference/ideation-template.md
- ideation/reference/questions-extended.md
Let's start ideation session about: "$ARGUMENTS"This is a pattern worth noting: if you plan to use skills only with small models, consider converting them to commands. Bigger models handle skill matching pretty well — they load the skill, read reference files, and follow the flow. Small models need the explicit instruction chain that a command provides.
Qwen 3.5 27B Results (Dense)
I ran all 4 quantization variants on the same task: ideation for “Add audio notes using Cactus SDK” in my Aily app. Full evaluation: Qwen 3.5 27B Quantization Comparison.
| Rank | Model | Score | Session Time | Key Strength |
|---|---|---|---|---|
| 1 | UD Q8_K_XL | 43/50 | 16 min | Contradiction detection, quantified benchmarks |
| 2 | Q8_0 | 41/50 | 16 min | Best question quality, vivid language capture |
| 3 | UD Q4_K_XL | 35/50 | 10 min | Workspace context usage, technical grounding |
| 4 | Q4_K_M | 29/50 | 10 min | Clean flow, no skipped steps |
Q8_K_XL won. It caught the Cactus offline contradiction — the user wanted offline-first but mentioned sending audio to servers. Only this variant named it directly. It also produced quantified success criteria (95% accuracy, <30s for 5-min recording) and separated MVP from v2 cleanly.
Q8_0 was the creative one. It preserved “walking with my dog” and “precious ideas” — phrases the other variants sanitised. But it took 16 minutes for 4 rounds.
Q4 variants struggled. Q4_K_M hallucinated open questions — added “notification when transcription completes” and " audio format support" that were never discussed. Q4_K_XL was better but still missed contradiction detection.
Higher quantization = better reasoning. Q8 variants scored 41-43. Q4 variants scored 29-35. The gap is real.
You can read the full session results for each model:
- Qwen 3.5 27B Q4_K_M session
- Qwen 3.5 27B Q8_0 session
- Qwen 3.5 27B UD Q4_K_XL session
- Qwen 3.5 27B UD Q8_K_XL session
Qwen 3.5 35B A3B Results (MoE)
Same task, MoE architecture. Full evaluation: Qwen 3.5 35B A3B Quantization Comparison.
| Rank | Model | Score | Session Time | Key Strength |
|---|---|---|---|---|
| 1 | UD Q8_K_XL | 34/50 | 11 min | Deepest workspace context, cleanest round theming |
| 2 | UD Q4_K_XL | 31/50 | 18 min | Most open questions (10), most risks (5) |
| 3 | Q8_0 | 30/50 | 11 min | 6 rounds, comprehensive MVP, good pushback |
| 4 | Q4_K_M | 22/50 | 8 min | Fastest session |
The MoE models are faster. All 35B sessions finished in 18 minutes or less. But speed comes at a cost.
Round theme bleeding is the main problem. Q4_K_M asked constraint questions (“What would make this a bad idea?”) in round 1 — that is a round 3 topic. Q4_K_XL repeated “What have you tried before” across both round 1 and round 2. The sparse activation pattern of MoE makes it harder to maintain strict conditional logic.
Accuracy failures are worse. Q4_K_M hallucinated workspace context — claimed to know Aily’s architecture without
reading app_overview.md. UD Q4_K_XL changed the user’s stated 45% success metric to 20% in the ideation doc. These are
not minor issues.
UD Q8_K_XL was the best of the group. It read pubspec.yaml for dependency details — the deepest workspace scan of
any 35B model. It matched session metrics exactly in the ideation doc (95% accuracy, 45% adoption). But even it accepted
vague “Yes” answers to non-yes/no questions.
You can read the full session results:
- Qwen 3.5 35B A3B Q4_K_M session
- Qwen 3.5 35B A3B Q8_0 session
- Qwen 3.5 35B A3B UD Q4_K_XL session
- Qwen 3.5 35B A3B UD Q8_K_XL session
Dense vs MoE: The Architecture Gap
Full comparison: Dense vs MoE Comparison.
| Criterion | 27B Dense Avg | 35B MoE Avg | Delta | Winner |
|---|---|---|---|---|
| Skill Flow Adherence | 4.25 | 3.50 | +0.75 | Dense |
| Question Quality | 4.00 | 3.25 | +0.75 | Dense |
| Round Thematic Rigor | 4.00 | 2.75 | +1.25 | Dense |
| Contradiction Detection | 3.50 | 2.75 | +0.75 | Dense |
| Vivid Language Capture | 3.50 | 3.00 | +0.50 | Dense |
| Workspace Context Usage | 4.50 | 3.75 | +0.75 | Dense |
| Doc Completeness | 4.50 | 4.25 | +0.25 | Dense |
| Doc Accuracy | 4.25 | 3.50 | +0.75 | Dense |
| Document Polish | 4.25 | 3.50 | +0.75 | Dense |
| Session Pacing | 4.00 | 3.50 | +0.50 | Dense |
| Average Total | 36.50 | 31.75 | +4.75 | Dense |
Dense wins on every criterion. The largest gap is Round Thematic Rigor (+1.25). Dense models keep round boundaries clean — Problem questions stay in round 1, Constraint questions stay in round 3. MoE models bleed themes across rounds.
Where MoE is competitive:
- Session Pacing — MoE is faster. All 35B sessions ≤18 min. Dense ranged 10-16 min.
- Doc Completeness — MoE UD Q4_K_XL produced the most comprehensive doc (10 open questions, 5 risks).
Quantization matters more than architecture at Q4. The 35B MoE Q8_K_XL (34) beats the 27B Dense Q4_K_M (29) by 5 points. Upgrading quantization has a bigger impact than switching architectures.
Best Dense: 27B UD Q8_K_XL (43/50). Best MoE: 35B UD Q8_K_XL (34/50). The gap is 9 points. For structured conversational tasks, Dense is the better architecture.
How to Improve the Skill
The evaluation revealed 18 specific failure modes. Full list: Skill Improvements.
Here are the most impactful ones:
1. Vivid language is lost during Q&A, not just at write time
The rule “do not sanitise vivid language” only appears in Step 5. By then, models paraphrase user answers for 4-5 rounds. Phrases like “I lost my 1 mln dollar idea” are gone from context.
Fix: Add to Step 3: “When reflecting user answers, quote their exact words in quotes. Do not paraphrase vivid or emotional language.”
2. No guard against hallucinated content
Q4_K_M added “notification when transcription completes” — never discussed. Nothing in the skill prevents this.
Fix: Add to Step 5: “Every item in the ideation doc must trace to something the user said. If you can’t point to a specific user answer, do not include it.”
3. Contradiction detection is too passive
“Name contradictions when you spot them” — only Q8_K_XL did this well. Others accepted “I don’t know” without follow-up.
Fix: Add examples: “When a user answer conflicts with an earlier answer, say: ‘You said X earlier, but now Y — which is closer to the truth?’”
4. Round themes bleed into each other
Rounds 2 and 3 had overlapping questions across most models.
Fix: Add negative constraints per round: “Round 1 — Focus on what’s broken. Do NOT ask about solutions or workarounds yet.”
5. “I don’t know” is accepted as final
The skill handles “it depends” but not “I don’t know”. Q4_K_M accepted it and moved on.
Fix: “Never accept ‘I don’t know’ as final. Respond: ‘What’s your best guess?’ or ‘What would need to be true for you to have an opinion?’”
6. Stop detection is fragile
Some models asked “Ready to write this up?” even when new threads existed. Others skipped straight to writing when the user said one sentence.
Fix: “Do NOT detect stop unless the user uses explicit stop language: ‘wrap it up’, ’that’s enough’, ’let’s write this up’, ‘ready for PRD’. A short answer is not a stop signal.”
7. MoE models struggle with structural rules
Round thematic rigor averaged 2.75/5 for MoE vs. 4.0/5 for Dense. This is likely an architecture limitation, not fixable via instructions alone. Adding explicit “FORBIDDEN in this round” lists per round with specific question examples helps.
8. Models change user’s stated metrics
35B A3B UD Q4_K_XL wrote “20% of the time” when the user said “45%”.
Fix: “Success criteria and metrics must use the exact numbers the user provided. Never adjust user-stated targets.”
What I Think About the Results
The biggest surprise was not which model won — I expected Dense to outperform MoE on structured tasks. The surprise was how close the results are across quantizations. Q4_K_M scored 29, Q8_K_XL scored 43. Same model, same architecture, same skill. The quantization level alone changed the output quality by 14 points. That tells me the model itself is capable — the bottleneck is how much reasoning quality survives the quantization.
MoE was disappointing for this task. I wanted it to work because it is faster. But round theme bleeding is a dealbreaker. If the model cannot keep “ask about problems” separate from “ask about constraints” within a single conversation, it cannot handle any structured workflow — not just ideation. I will test MoE again after improving the skill instructions, but I expect the architecture limitation to remain.
The skill itself is not good enough yet. 18 failure modes from 8 runs means the instructions are too vague in critical places. The most damaging failures — hallucinated content, changed metrics, sanitised language — all come from missing guardrails. The skill says “do not sanitise vivid language” in Step 5 but never tells the model to preserve it during Q&A. It says “name contradictions” but never gives an example of what that looks like. These are fixable problems.
My plan is to apply the 18 improvements, run the experiment again, and see if the scores improve. If a better skill pushes the Q4 variants from 29 to 35+, that changes the calculus — it means lower quantizations become viable with better instructions. That would be a big win for running models on limited hardware.
Key Points
- Dense architecture outperforms MoE on structured conversational tasks — 4.75 point average gap across all criteria
- Q8_K_XL is the best quantization for both architectures — higher bit-width preserves reasoning quality
- Quantization matters more than architecture at Q4 — upgrading from Q4 to Q8 has a bigger impact than switching from MoE to Dense
- The best model is Qwen 3.5 27B UD Q8_K_XL at 43/50 — it catches contradictions, produces quantified benchmarks, and finishes in 16 minutes
- MoE is faster but less rigorous — all MoE sessions ≤18 min but round themes bleed and contradictions go unnamed
- The skill needs 18 improvements — most are guardrails against hallucination, theme bleeding, and language sanitisation
- Vivid language needs protection from round 1 — not just in the document writing step
- Structural rules need negative constraints — tell models what NOT to ask in each round, not just what to ask